
-
油茶是山茶科(Theaceae)山茶属 (Camellia )木本油料树种,目前在国内主要的栽培种除了普通油茶 (Camellia oleifera Abel.),还包括小果油茶 (Camellia meocarpa Hu)、越南油茶 (Camellia vietnamensis T. C. Huang ex Hu) 和博白大果油茶 (Camellia gigantocarpa Hu et Huang) 等。其分布区域主要集中在湖南、福建等南方省份,由于油茶及其各类产品具有独特的食用、药用价值,尤其是籽油中含有脂肪酸、植物甾醇、角鲨烯和维生素E等多种活性成分,因此备受生产者及消费者的欢迎[1]。油茶与椰子 (Cocos nucifera)、油橄榄 (Olea europaea)、油棕 (Elaeis guineensis) 并称为世界4大木本油料树种[2]。自20世纪60年代起,我国通过油茶育种工作已选育出近200个优良无性系,另外,还选育出众多的农家良种、优良家系,为油茶的高品质和高产量奠定了基础[3]。近年来,海南省不少单位和种植户积极尝试,引进外省品种种植于海南,但由于海南省气候具有高温高湿的特点,外来苗木在此不仅适应性和抗逆性差,而且易受病虫害侵害,导致成活率低,幼苗即使成活也表现出长势不佳、长速缓慢的生长趋势[4]。目前,海南省已初步选取了20个海南本地油茶优良单株作为应急品种在全省推广种植。因此,比较和研究这些优良单株的遗传和生理特性,特别是其抗病性和抗逆性,早日选出适合海南种植的品质优良的油茶品种,是海南油茶产业发展的当务之急。
转录组是指某个物种或者特定的细胞类型产生的所有转录本的集合[5],包括转录本的数量、特定发育阶段的表达动态、转录后的修饰以及非编码RNA的调控表达情况等[6],以转录组分析为基础,能够更加全面深入地研究特定物种的基因表达、结构以及功能,从而进一步了解特定的生理特性背后的的分子机理[7]。转录组测序(RNA-Seq)是在深度测序的基础上进行转录组分析的技术,2008年首次面世,随后在多个领域被广泛投入应用[8],该技术可用于确定基因的表达模式、发现新转录本、非编码RNA的调控机制和单细胞转录组等多个方面的研究[9],相比基因组,它更具有时间性和空间性,目前已应用于人参[10]、毛地黄[11]、重楼[12]、罗勒[13]、沙棘[14]等多种药用植物的研究。转录组测序技术可为油茶的基因功能及生理特性研究提供新的手段。
目前,海南省认定的油茶优良单株所处的地理位置、树龄、水肥环境等有较大差异,其芽砧苗也尚未大规模推广种植并结实。因此,笔者选取了2个海南油茶优良单株为材料,采用新一代高通量Illumina转录组测序技术,分别对这2个优良单株的两年生芽砧苗的健康成熟叶片进行转录组分析,研究和比较2个优良单株的无性系基因表达的差异与共同点,为油茶的品种改良及优良品种选育奠定基础。
HTML
-
以海南省林木品种审定委员会选取认定的“万海1号”和“万海4号”这2个海南油茶单株为试验材料,于2018年12月在海南大学儋州校区的油茶育苗圃进行样品采集,选择2个优良单株的两年生长势一致的健康芽砧苗各20株,每株随机采集新鲜成熟叶片,混合后迅速放入液氮保存,用于转录组测序。
-
从样品中提取总RNA后,转录组测序过程委托赛哲生物公司完成。用带有Oligo (dT)的磁珠富集mRNA,使用fragmentation buffer将mRNA分解成短片段,反转录后经QiaQuick PCR试剂盒纯化回收,建立cDNA文库。使用Illumina HiSeqTMPE150对构建的测序文库进行测序。使用 Trinity对原始数据进行组装,随后注释到NR、KOG、KEGG、Swiss-Prot数据库,根据最佳比对结果获得蛋白质功能注释。使用 blastp 与 OrthoMCL 联用的方法来找出物种间同源的 Unigene,在得到物种间同源与特有基因家族后,将各类基因家族在两物种中分别包含的基因数(即基因家族拷贝数)分别统计,找出各物种特有的基因家族,分别对其进行功能注释、KEGG富集分析、GO富集分析。使用软件MISA(
http://pgrc.ipk-gatersleben.de/misa/ )对各个物种的单拷贝同源基因Unigene进行搜索,进行SSR分析。
1.1. 实验材料
1.2. 样品处理及转录组数据库分析流程
-
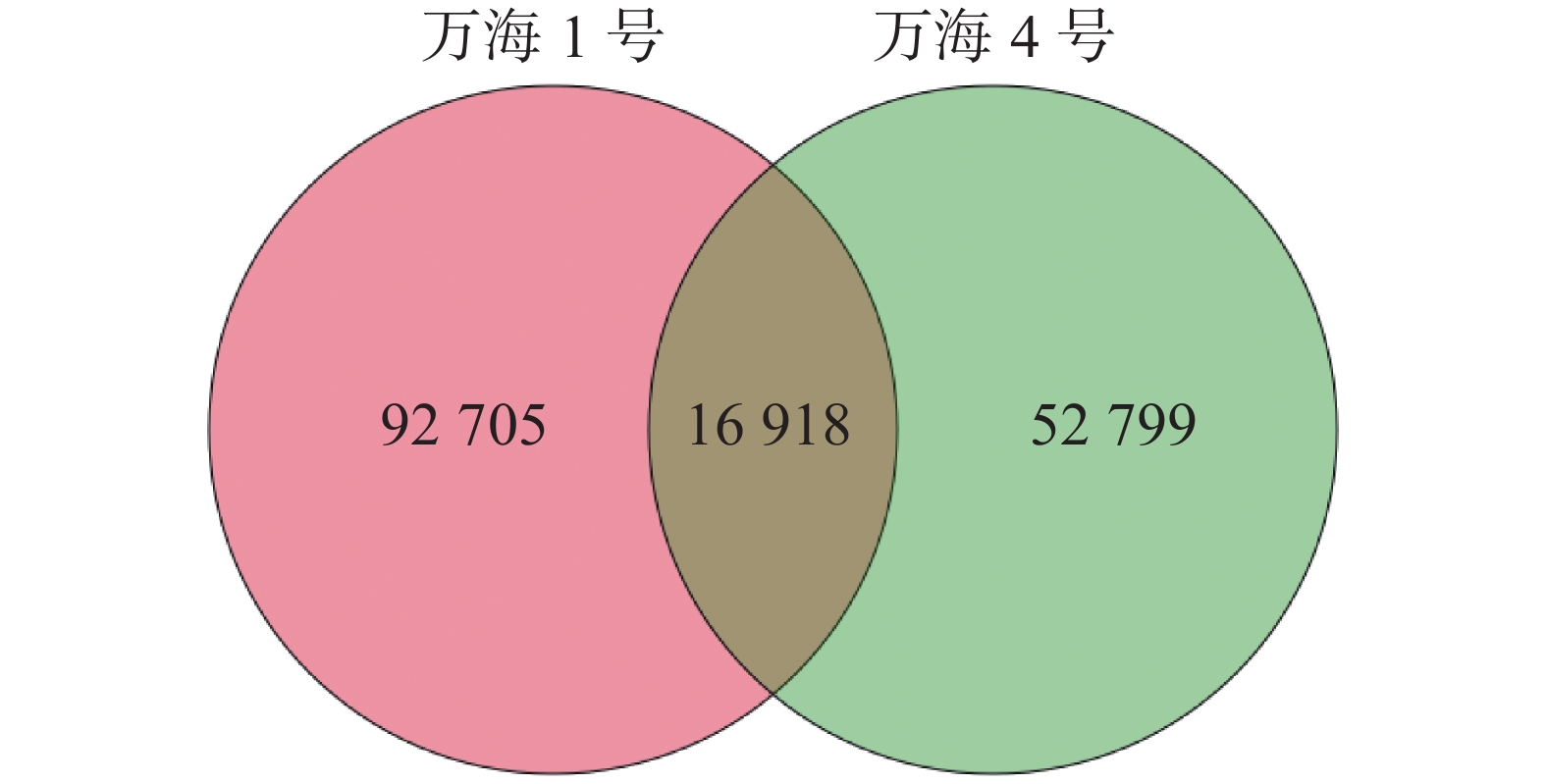
使用 Trinity对2个油茶样本进行组装,得到其转录组参考序列。如表1所示,共对185 698条基因进行了测序。“万海1号”和“万海4号”2个样本的N50长度分别为809 bp和912 bp,“万海1号”的最大基因长度为21 213 bp,最小为201 bp;“万海4号”的最大基因长度为21 867 bp,最小为201 bp。“万海1号”和“万海4号”的GC值均较高,分别为41.66%和43.57%,表明测序数据质量良好。对2个样本中各类基因和基因家族的数目进行统计,结果(图1)表明,“万海1号”和“万海4号”同源的基因及基因家族共有16 918个,“万海1号”特有的基因有92 705个,“万海4号”特有的基因数则为52 799个。
样品
Sample基因数/个
GenesN50 GC/%GC
percentage最大长度/bp
Maximum length最小长度/bp
Minimum lengthCDS 蛋白数
Proteins“万海1号” 113 846 809 41.66 21 213 201 52 549 52 549 “万海4号” 71 852 912 43.57 21 867 201 36 930 36 930 Table 1. Transcriptome analysis of 2 clones derived from 2 elite individual plants of Camellia vietnamensis
Figure 1. Venn diagram showing gene families between the samples
-
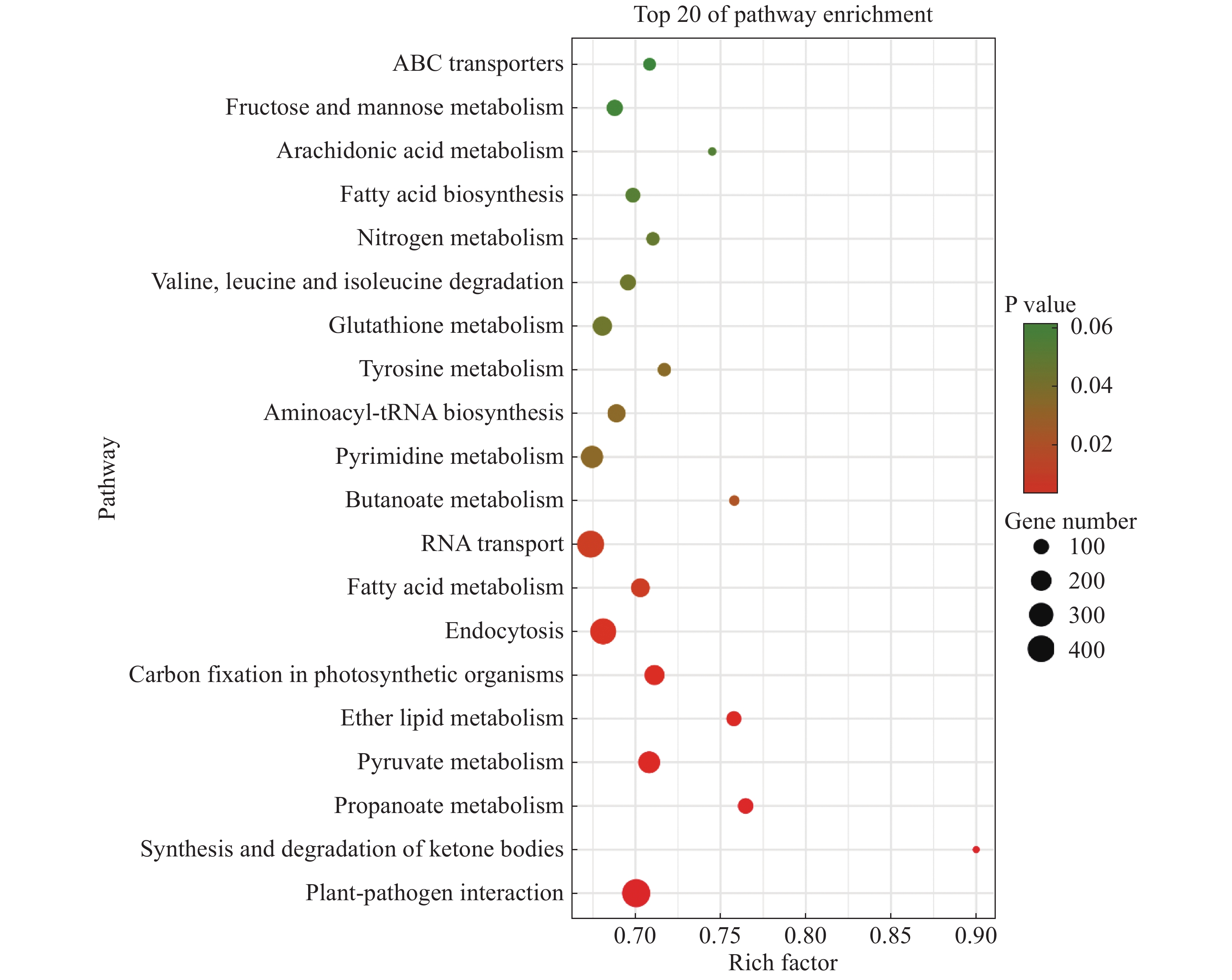
将2个样本的Unigenes注释到KEGG数据库进行比对,得到它们的特有基因KEGG富集分析气泡图,从而找出物种特有基因中显著性富集的pathway。“万海4号”与“万海1号”油茶的比较结果(图2)表明,“万海4号”以核糖体途径的基因丰度最高,约为600条,其次是碳代谢和氧化磷酸化途径,三者的P值均小于0.03。在“万海4号”所有的代谢途径中,富集因子最大的是单萜类生物合成途径,富集因子约为0.79;其次是油菜素的生物合成途径,富集因子约为0.73。值得注意的是,在“万海4号”排名前20的富集途径中,出现了倍半萜和三萜生物合成、油菜素类固醇生物合成、类固醇生物合成和单萜类生物合成等与植物次生代谢相关的途径。“万海1号”的KEGG富集结果中,以植物病原体互作途径基因丰度最高,富集了651条基因,占总数的5.26%,这可能与植物的抗病性相关;其次是RNA转运途径与内吞作用途径。在所有的代谢途径中,富集因子最大的是酮体的合成与降解途径,富集因子约为0.90;其次是丙酸酯代谢和醚脂质代谢途径(图3)。在万海1号的前20条KEGG途径中,出现了脂肪酸生物合成及脂肪酸代谢等与脂肪酸相关的途径,二者分别富集了136和239条基因,这可能与茶籽及茶油品质相关。

Figure 2. Dotplot of KEGG enrichment analysis results of specific genes of Clone ‘Wanhai4’
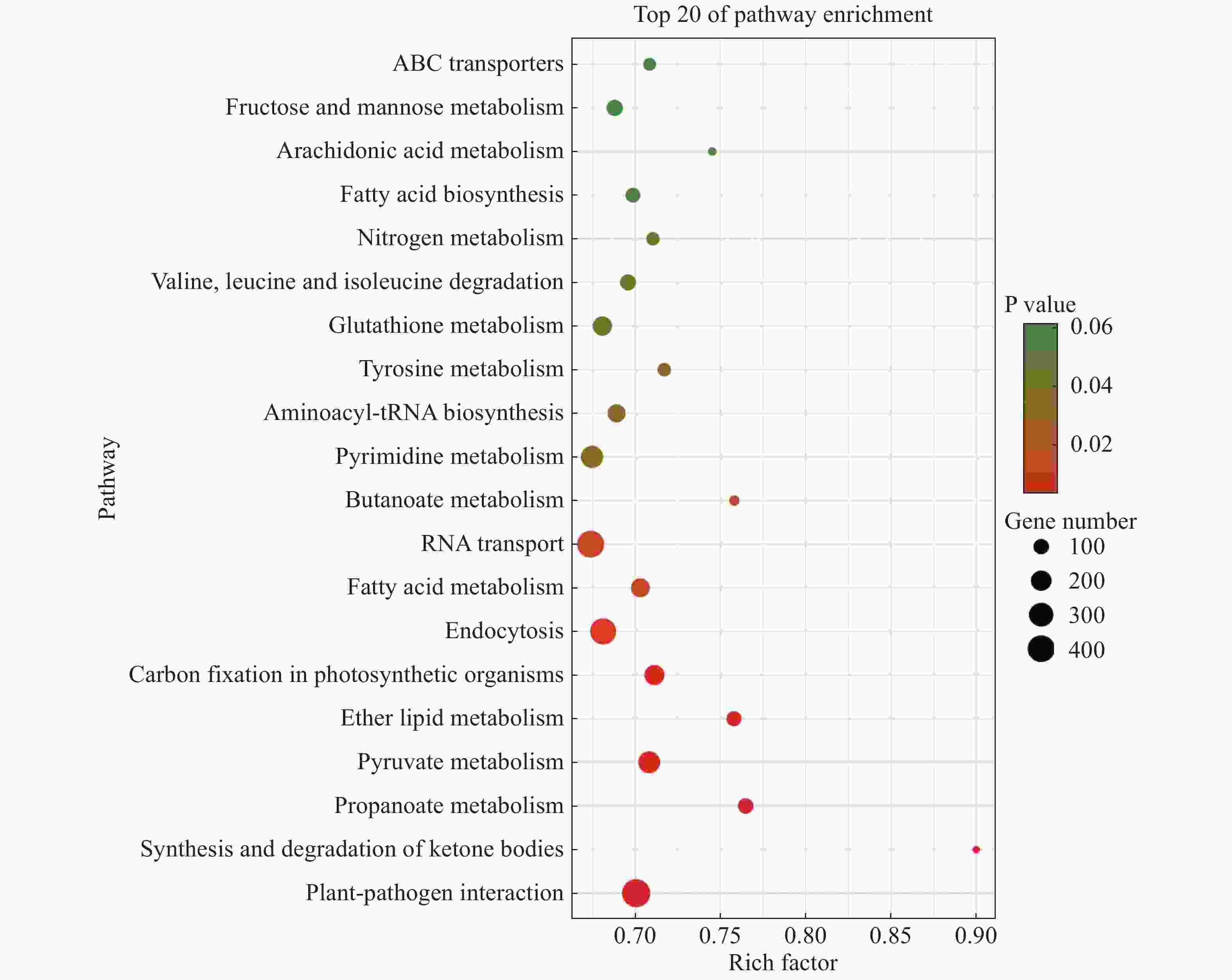
Figure 3. Dotplot of KEGG enrichment analysis results of specific genes of Clone ‘Wanhai1’
在此基础上,对2个样本的共有基因进行表达谱分析,结果(图4)表明,“万海4号”油茶在油菜素类固醇生物合成、倍半萜和三萜生物合成、单萜类生物合成和类固醇生物合成等与植物次生代谢相关的4个途径的表达量都明显高于“万海1号”,而“万海1号”油茶在植物病原体互作、脂肪酸降解与脂肪酸生物合成等途径的表达量都高于“万海4号”,这和KEGG富集的结果相一致。
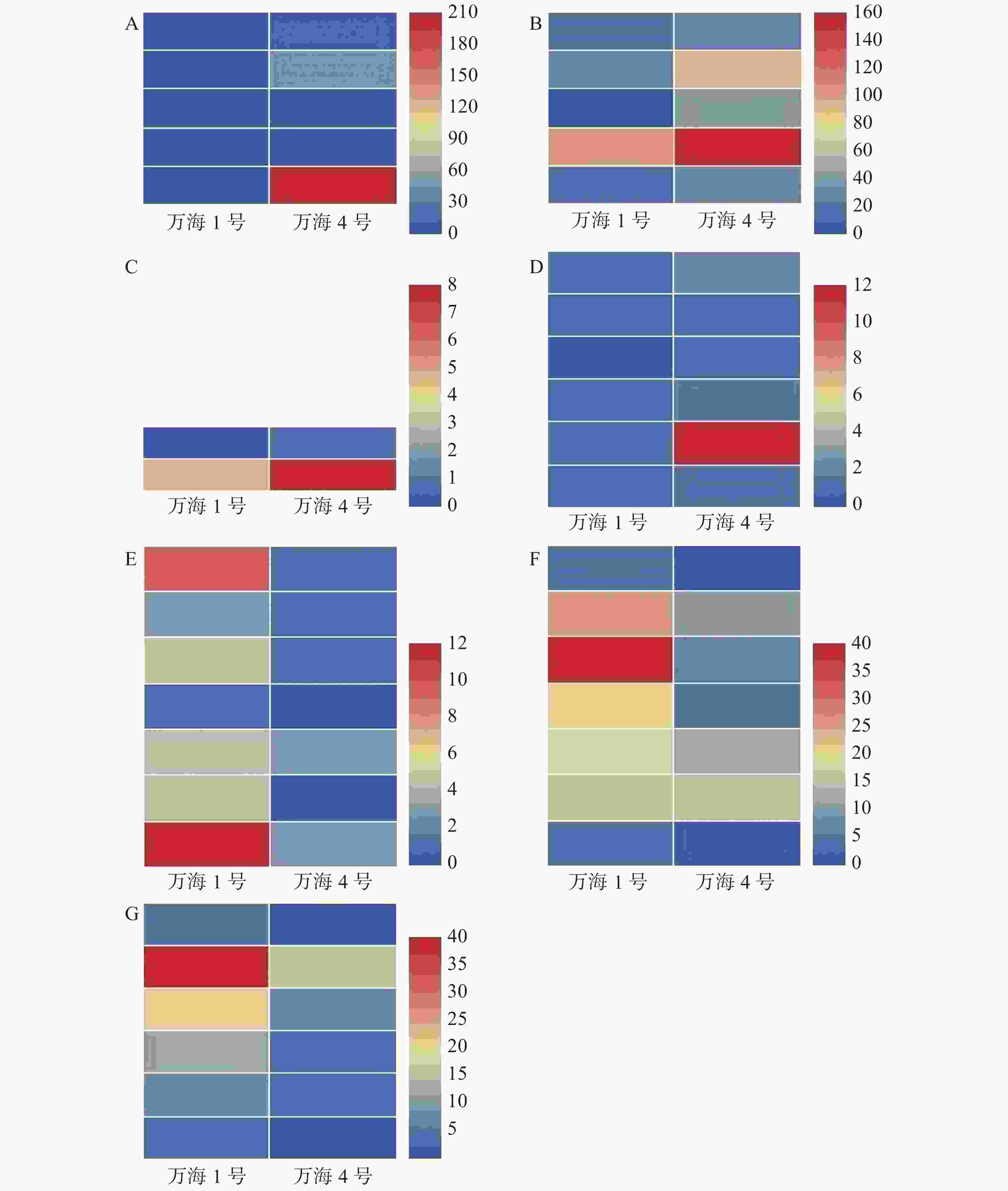
Figure 4. Gene expression profile of shared genes
对2个样品中富集特异性基因较多的KEGG通路进行统计,所得结果具有一定的相似性,2个样品共同的基因高富集途径见表2。其中,有2条与代谢相关的途径:碳代谢和氨基酸的生物合成;有4条与遗传信息处理相关的途径,分别是内质网中的蛋白质加工、核糖体、RNA转运和剪接体;还有1条胞吞作用途径,则与细胞过程相关。富集到这些共同途径的基因对于越南油茶维持正常的生理功能可能起到了一定的调节作用。
KEGG_A_class KEGG_B_class 代谢通路 Pathway 富集基因数/个 Enriched genes “万海1号” “万海4号” 代谢 metabolism 全局和概述 Global and Overview 碳代谢 Carbon metabolism 519 422 遗传信息处理 Genetic
Information Processing折叠,分类和降解
Folding, sorting and degradation内质网中的蛋白质加工
Protein processing in
endoplasmic reticulum416 291 代谢 metabolism 全局和概述
Global and Overview氨基酸的生物合成
Biosynthesis of amino acids401 280 遗传信息处理 Genetic
Information Processing翻译
Translation核糖体
Ribosome393 729 细胞过程
Cellular Processes运输和分解代谢
Transport and catabolism胞吞作用
Endocytosis378 230 遗传信息处理 Genetic
Information Processing翻译
TranslationRNA转运
RNA transport415 242 遗传信息处理 Genetic
Information Processing转录
Transcription剪接体
Spliceosome347 220 Table 2. Statistics of KEGG enrichment pathway of 2 elite clones of Camellia oleifera
-
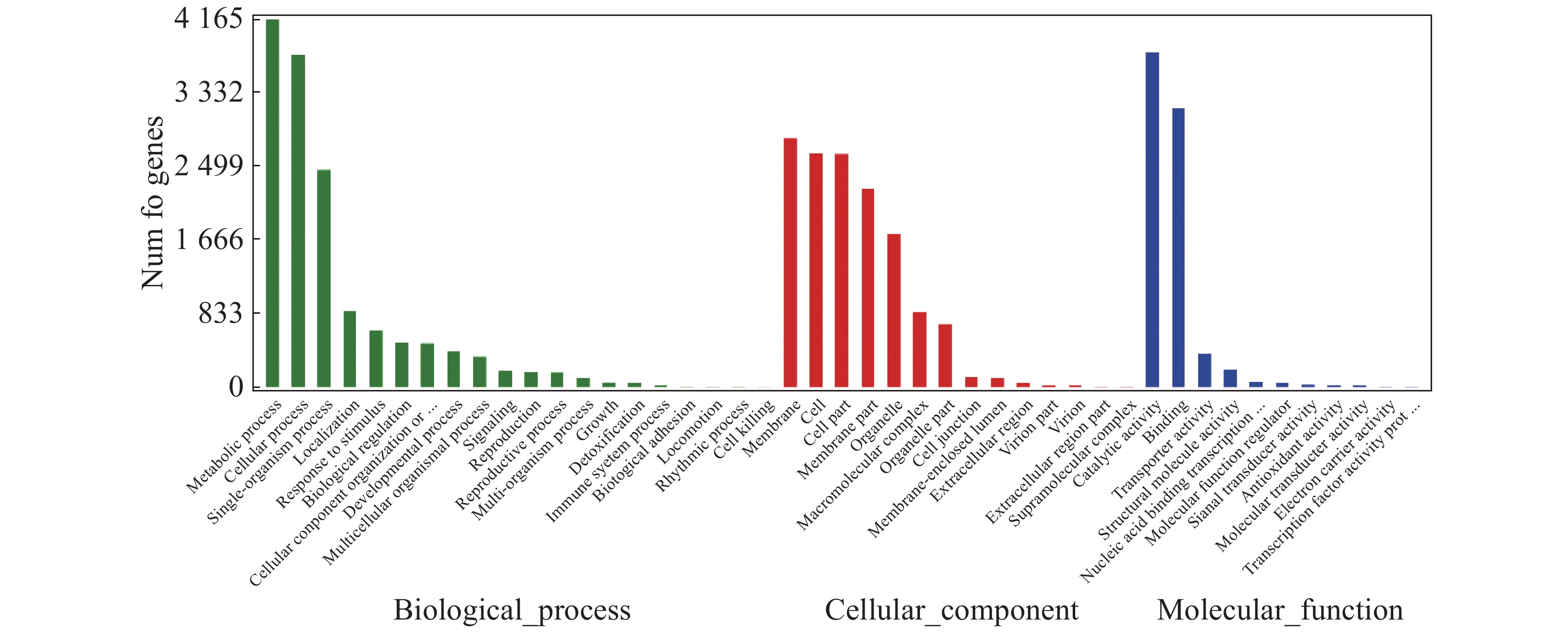
对“万海4号”和“万海1号”特有的差异表达基因进行GO富集分析,结果(图5)表明,“万海4号”的特有基因被聚集到生物过程、细胞成分和分子功能3大类,在生物过程大类中,代谢过程、细胞内过程、单组织过程所富集的基因较多;基因在细胞成分大类富集最多的3个途径分别是膜、细胞和细胞组分;而在分子功能大类中,催化活性和结合2个分支富集的差异基因较多。“万海1号”和“万海4号”GO富集分析的结果相似(图6)。
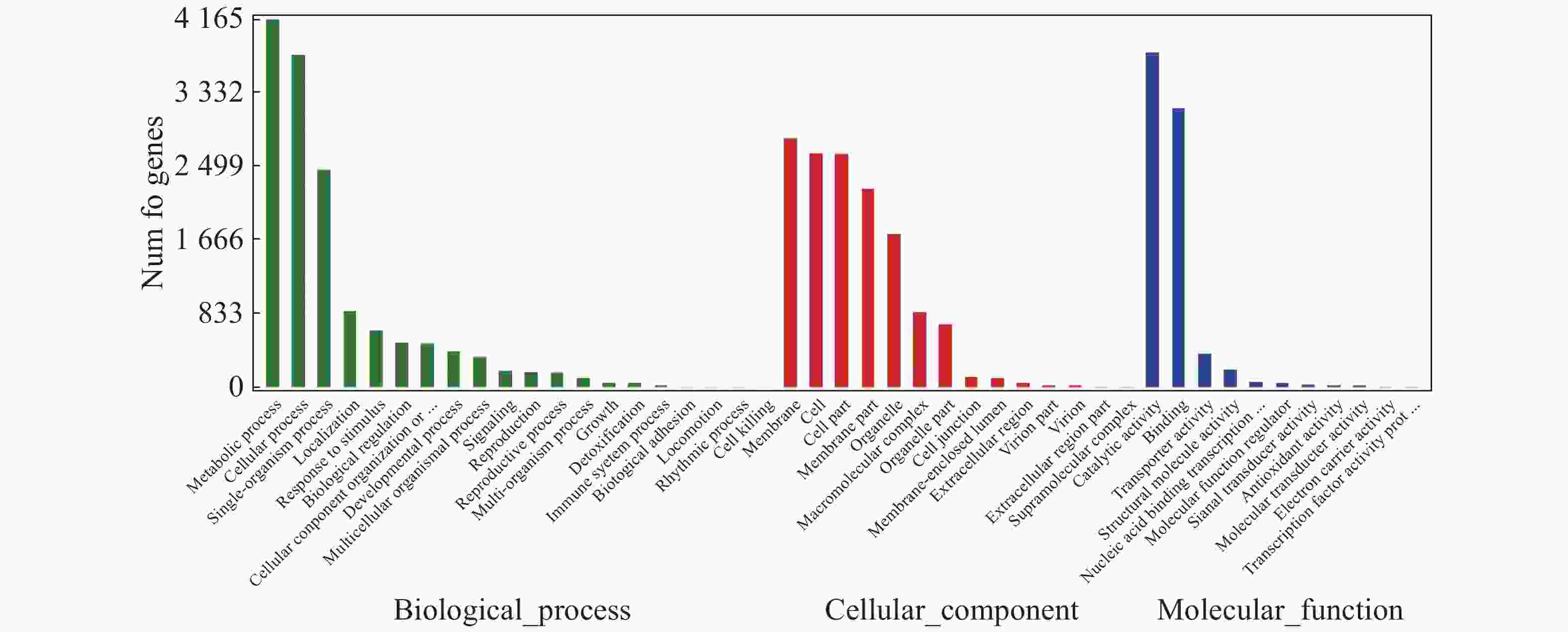
Figure 5. GO gene classification of specific genes in Clone ‘Wanhai4’
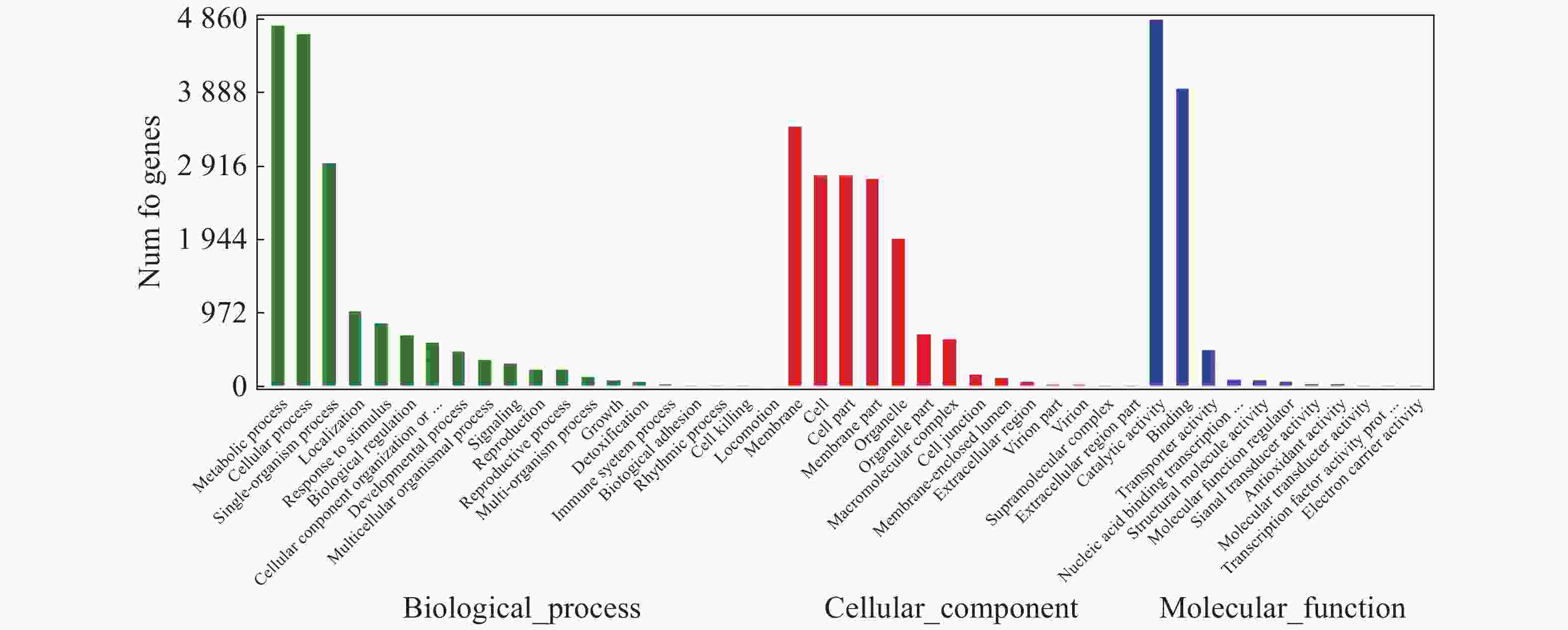
Figure 6. GO gene classification of specific genes in Clone ‘Wanhai1’
-
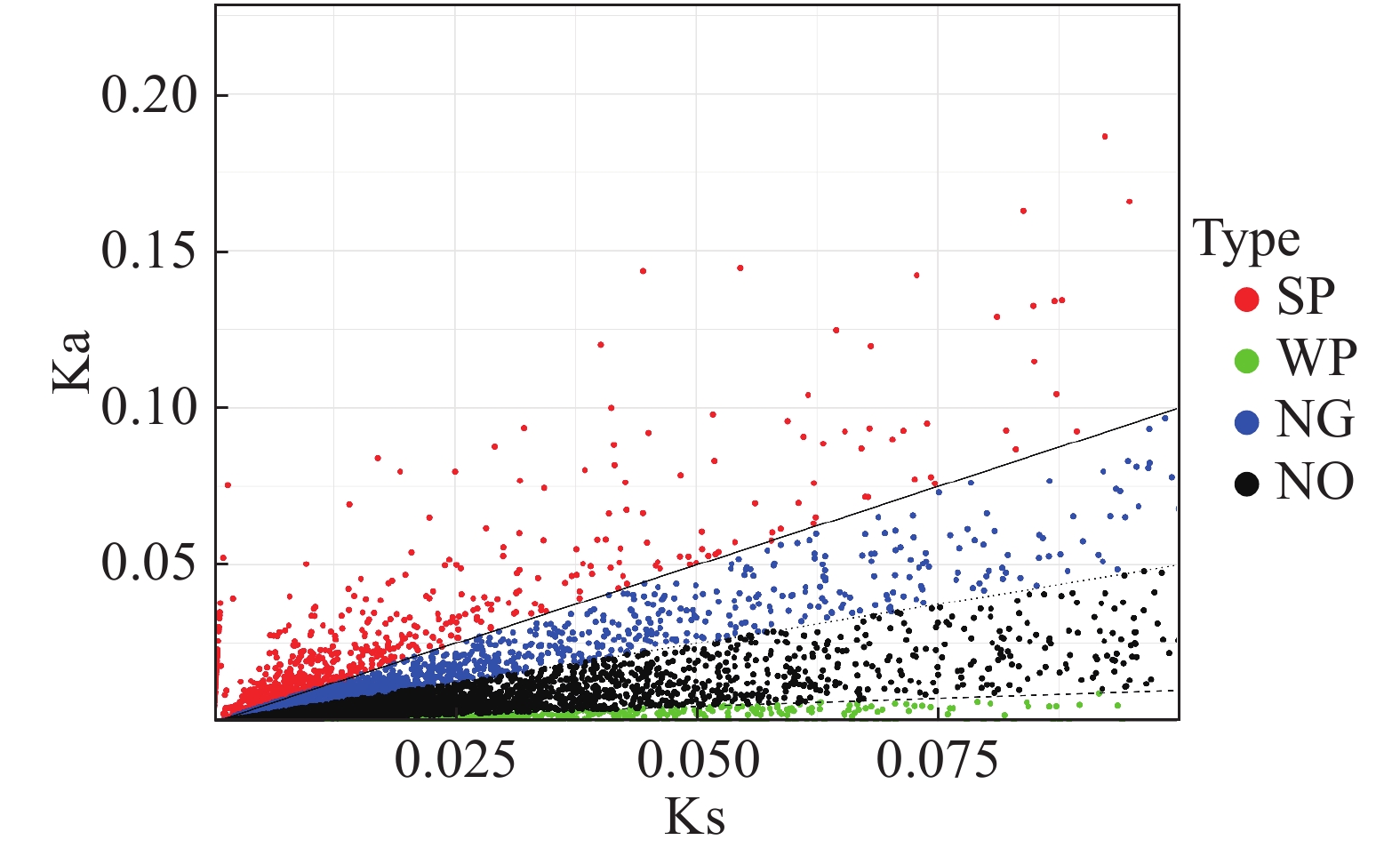
编码基因中Ka与Ks的比值可以用来估计选择压力。Ka/Ks值大于或小于1的基因表明该基因分别受到阳性或纯化选择。估算“万海4号”油茶和“万海1号”油茶中所有8 835对同源unigene对的Ka和Ks值,计算所有unigene对的Ka/Ks比值,结果(图7)表明,Ka和Ks值之间显著正相关,共有1 980个unigenes的Ka/Ks比值大于1,其余6 855个unigenes的Ka/Ks比值小于或等于1。
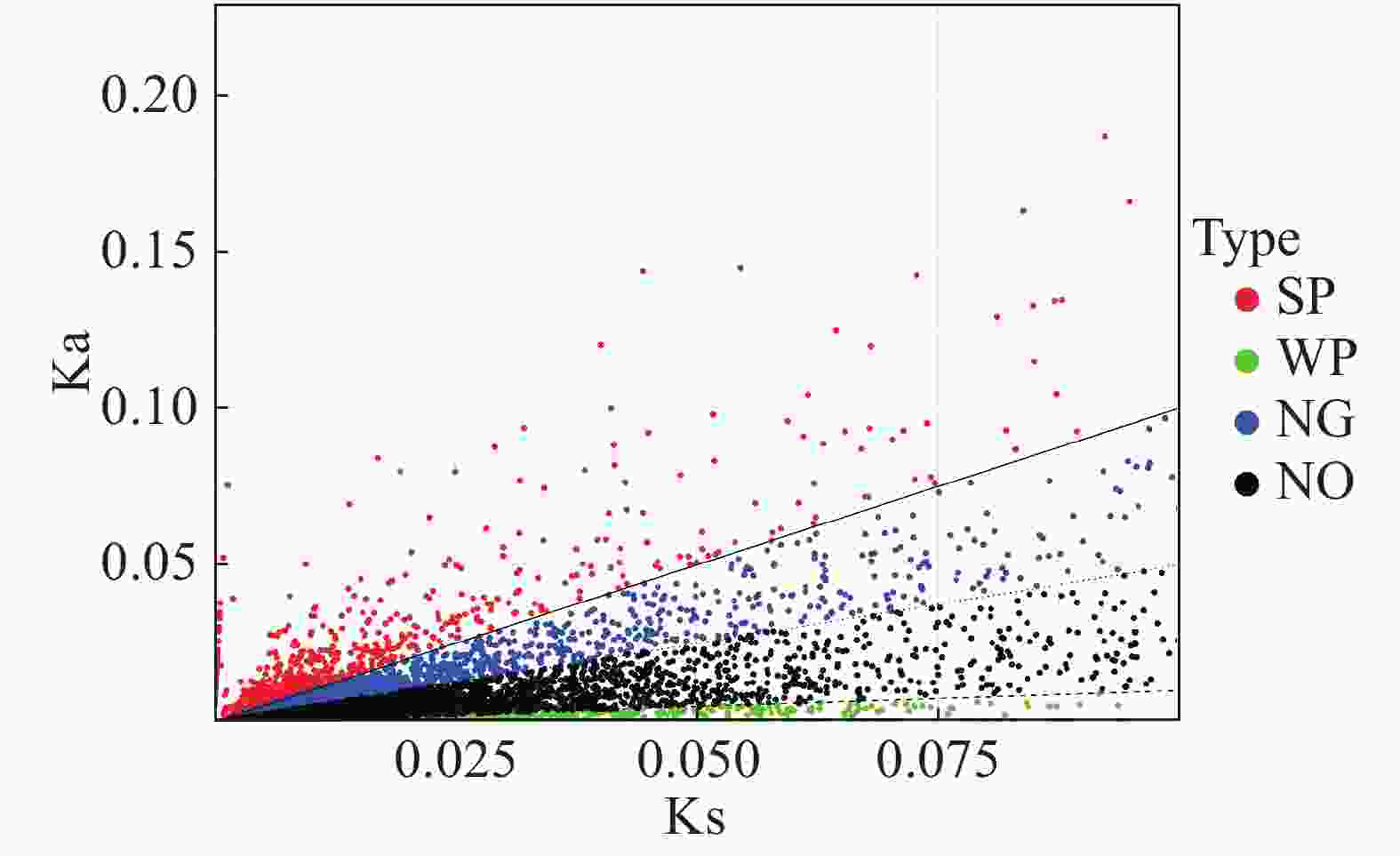
Figure 7. Scatter plots of Ka and Ks in Clones ‘Wanhai4’ and ‘Wanhai1’
对“万海1号”与“万海4号”单拷贝同源基因中受到强烈正向选择的基因(Strong Positive Select,SP)进行功能富集分析,GO注释的结果表明,基因被富集到生物过程、分子功能和细胞成分3个大类,在生物过程大类中,某些基因富集到与抗氧化能力相关的GO条目,如“GO:0006801-超氧化物代谢过程”,且P<0.01,呈极显著相关,而在分子功能大类中,部分基因富集到“GO:0016655-氧化还原酶活性,作为NAD(P)H,醌或类似化合物的受体”条目,也显示出与抗氧化能力的相关性(表3)。KEGG富集分析结果(表4)表明,单拷贝同源基因中受到强烈正向选择的基因多被富集到与氨基酸合成代谢相关的条目,如“精氨酸和脯氨酸代谢”、“嘌呤代谢”,以及与生物碱合成代谢相关的条目,如“莨菪烷、哌啶和吡啶生物碱的生物合成”、“异喹啉生物碱的生物合成”,且P值均小于0.05,显示出显著的相关性。
GO功能分类
GO classificationGO ID 功能描述
Function description注释基因数(占比)
Gene Number(Ratio)P-value Q-value 生物过程
Biological ProcessGO:0006801 超氧化物代谢过程
Superoxide metabolic process3 (1.06%) 0.001 007 0.521 483 GO:0000338 蛋白质树突化
Protein deneddylation2 (0.71%) 0.005 381 0.521 483 分子功能
Molecular FunctionGO:0004457 乳酸脱氢酶活性
lactate dehydrogenase activity2 (0.74%) 0.001 579 0.290 456 GO:0016655 氧化还原酶活性,作为NAD(P)H,
醌或类似化合物的受体
Oxidoreductase activity, acting on NAD(P)H,
quinone or similar compound as acceptor3 (1.11%) 0.005 501 0.327 781 GO:0070546 L-苯丙氨酸氨基转移酶活性
L-phenylalanine aminotransferase activity2 (0.74%) 0.007 537 0.327 781 细胞成分
Cellular ComponentGO:0044435 质体部分Plastid part 27 (10.63%) 0.000 816 0.074 252 GO:0009526 质体包膜Plastid envelope 16 (6.3%) 0.001 150 0.074 252 GO:0031967 细胞器包膜Organelle envelope 20 (7.87%) 0.002 151 0.074 252 GO:0031975 包膜Envelope 20 (7.87%) 0.002 216 0.074 252 GO:0009536 质体Plastid 38 (14.96%) 0.009 439 0.217 881 Table 3. GO enrichment for SP genes in Clones ‘Wanhai1’ and ‘Wanghai4’
途径 Pathway 注释基因数(占比) P-value Q-value Pathway ID 莨菪烷、哌啶和吡啶生物碱的生物合成
Tropane, piperidine and pyridine alkaloid biosynthesis5 (1.58%) 0.018 213 0.623 606 ko00960 精氨酸和脯氨酸代谢 Arginine and proline metabolism 8 (2.53%) 0.022 31 0.623 606 ko00330 基础切除修复 Base excision repair 7 (2.22%) 0.023 441 0.623 606 ko03410 RNA聚合酶 RNA polymerase 7 (2.22%) 0.027 78 0.623 606 ko03020 嘌呤代谢 Purine metabolism 17 (5.38%) 0.039 612 0.623 606 ko00230 异喹啉生物碱的生物合成 Isoquinoline alkaloid biosynthesis 4 (1.27%) 0.048 535 0.623 606 ko00950 Table 4. KEGG enrichment for SP gene in Clones ‘Wanhai1’ and ‘Wanhai 4’
-
在“万海1号”和“万海4号”2个样品的单拷贝同源基因中共检索到 11 949个 SSR 候选位点(表5)。“万海1号”序列总大小为18 736 662 bp,共检索到6 746个SSR 位点,包含SSR的序列数为4 937条,其中有1 36 4条序列包含1个以上SSR,化合物形成中存在的SSR数为848;“万海4号”序列总大小为16 440 557 bp,共检索到5 203个SSR 位点,包含SSR的序列数为3 990条,其中有956条序列包含1个以上SSR,化合物形成中存在的SSR数为604。
项目Statistical item “万海1号” “万海4号” 评估的序列总数
Total number of sequences examined17 377 16 405 评估序列总碱基量
Total size of examined sequences/bp18 736 662 16 440 557 识别的SSRs总数
Total number of identified SSRs6 746 5 203 包含SSR的序列数目
Number of SSR containing sequences4 937 3 990 包含1 个以上 SSR 的序列数目
Number of sequences containing more than 1 SSR1 364 956 以复合物存在的 SSR 数目
Number of SSRs present in compound formation848 604 二核苷酸
Di-nucleotide3 855 2 882 三核苷酸
Tri-nucleotide2 134 1 711 四核苷酸
Tetra-nucleotide253 195 五核苷酸
Penta-nucleotide158 131 六核苷酸
Hexa-nucleotide346 284 Table 5. Statistics of SSR types
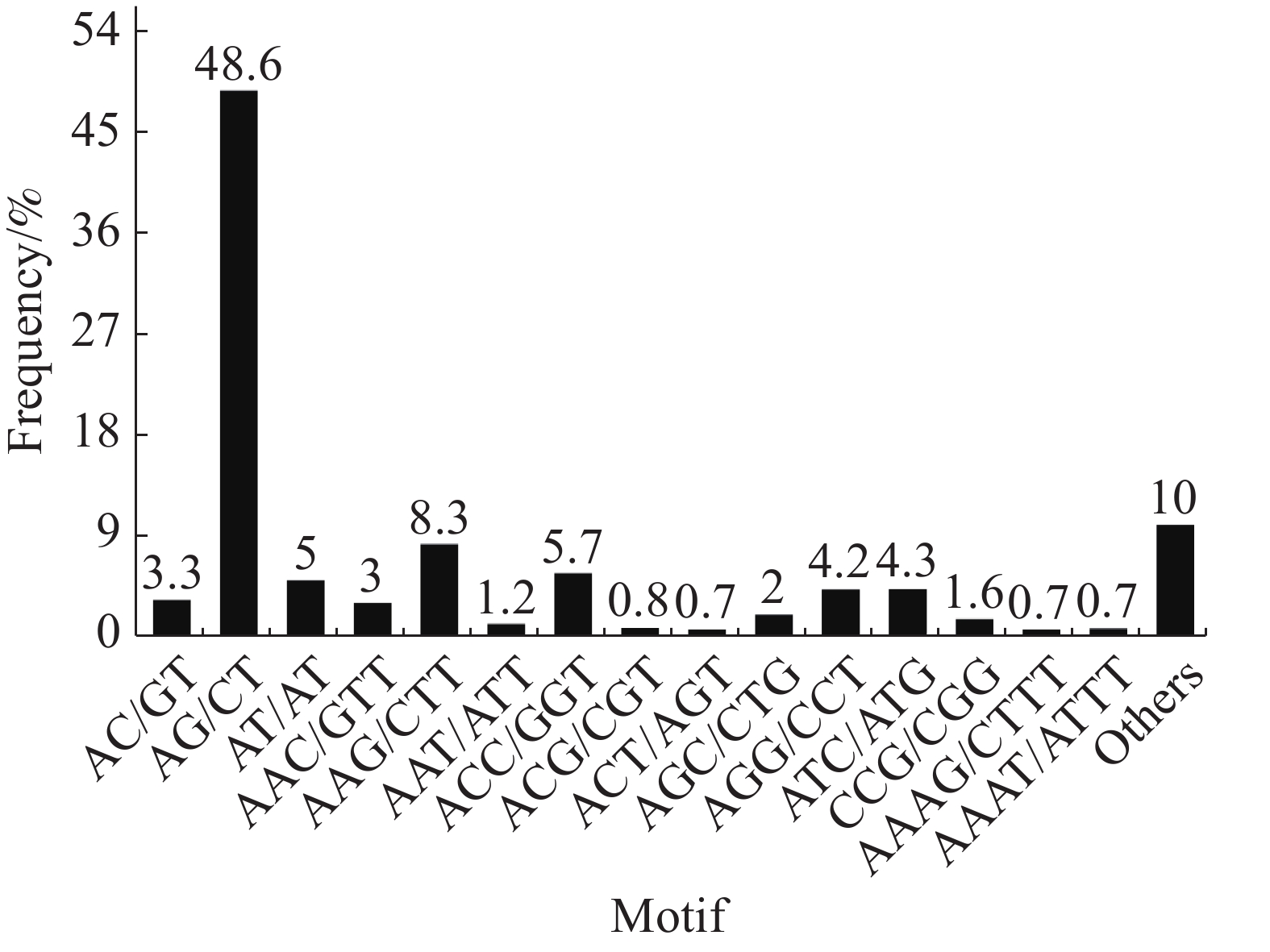
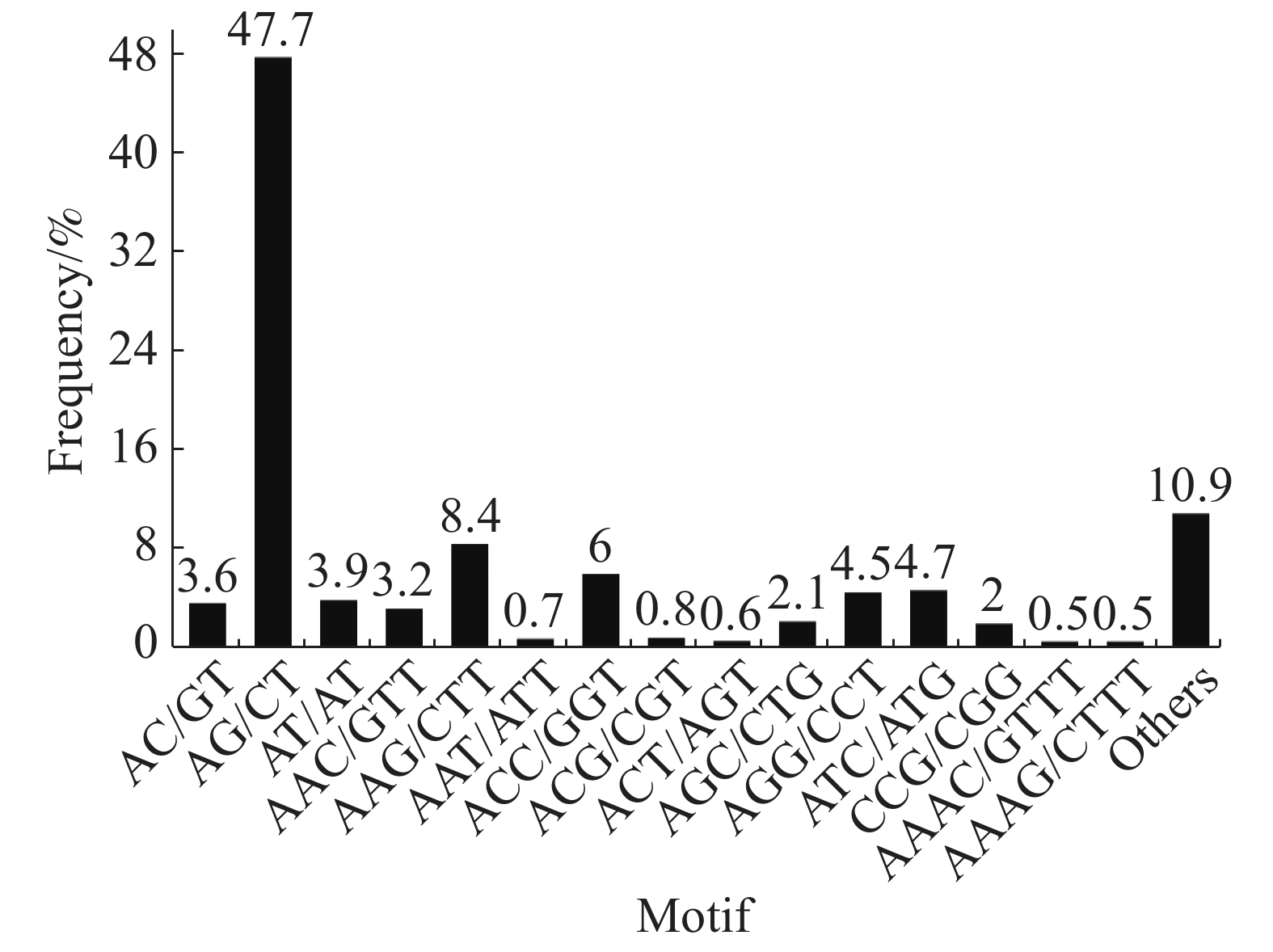
在SSR位点各碱基重复数量中,2个样品的占比大小相似,占比最大的是二碱基重复(“万海1号”中占56.9%,“万海4号”中占55.2%),其次是三碱基重复(“万海1号”中占31.8%,“万海4号”中占33%)。与“万海1号” 相比,“万海4号”中各碱基重复的类型数量均较为接近,且二者在二碱基、三碱基重复的优势基元类型上完全一致;不同之处在于“万海1号”的四碱基重复优势基元类型为AAAG/CTTT和AAAT/ATTT,而“万海4号”的四碱基重复优势基元类型为AAAC/GTTT和AAAG/CTTT(图8,9)。
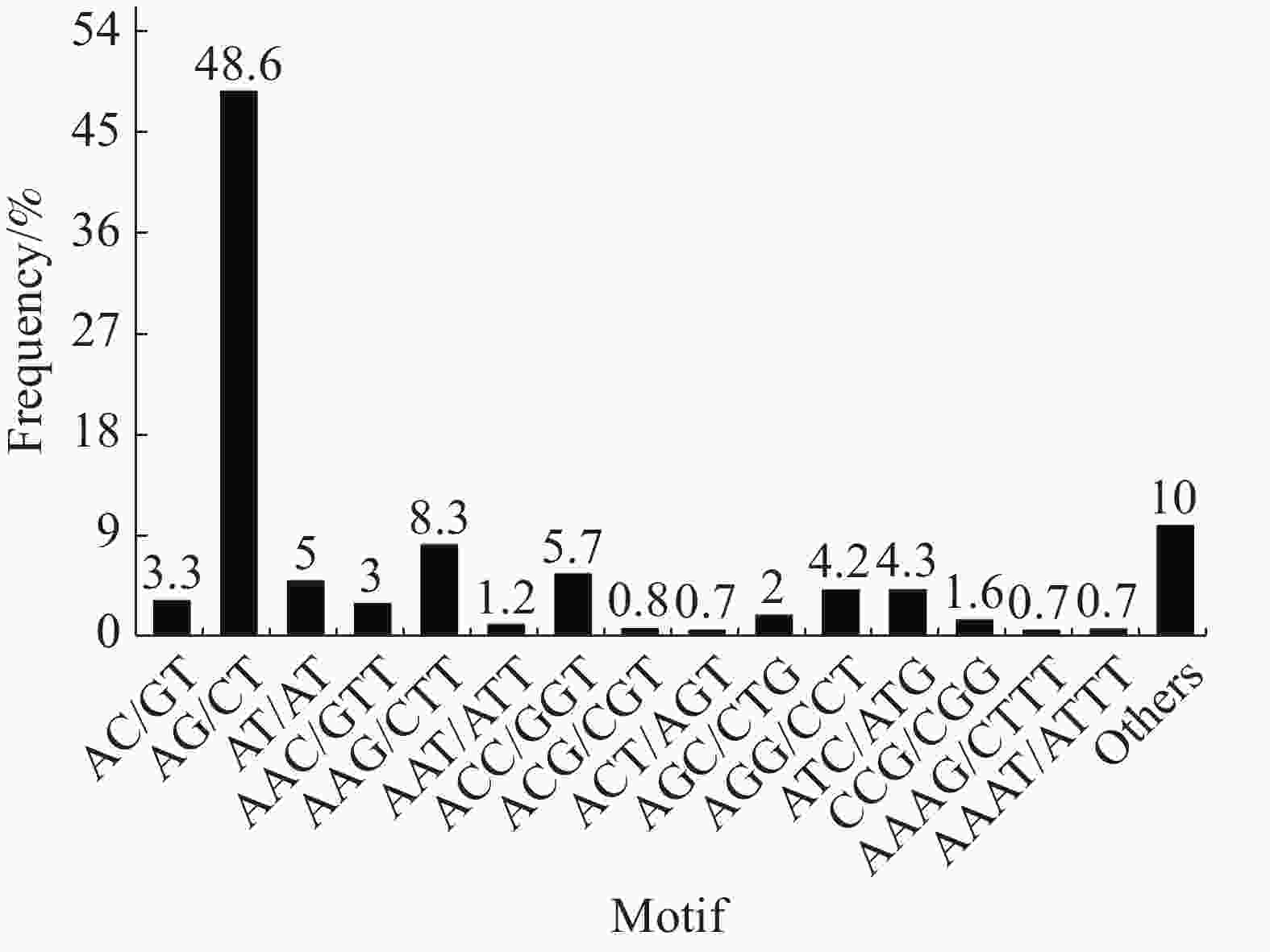
Figure 8. SSR distribution of single copy orthologs of Clone ‘Wanhai1`
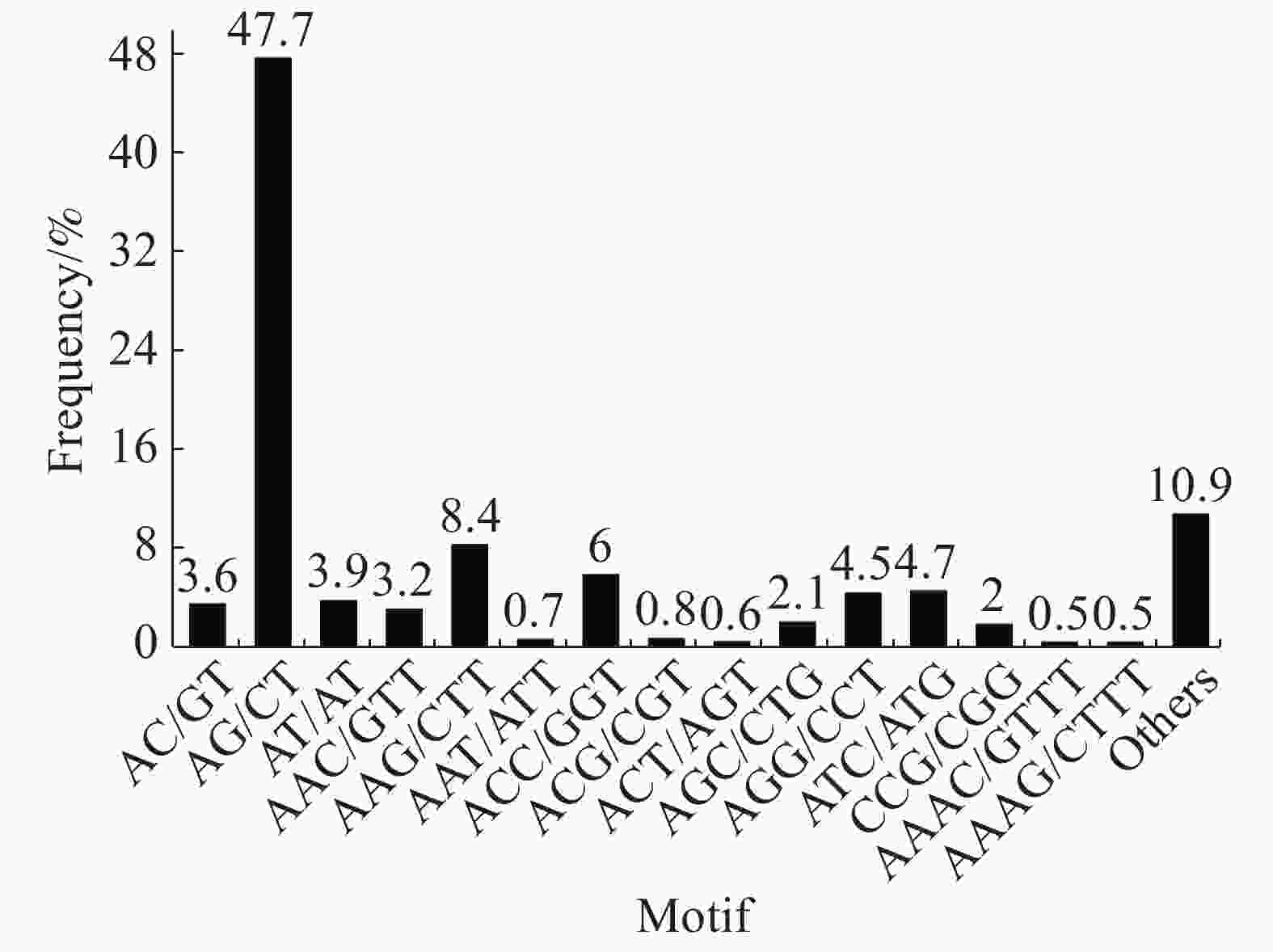
Figure 9. SSR distribution of single copy orthologs of Clone ‘Wanhai4’
2.1. 转录组基本信息分析
2.2. 特有基因分析
2.2.1. 特有基因KEGG富集分析
2.2.2. 特有基因GO富集分析
2.3. Ka/Ks 分析
2.4. 单拷贝同源基因SSR分析
-
转录组测序技术通过在单核昔酸水平进行检测,能够准确高效地获得某物种在不同时期最为全面的转录本信息。作为生物信息学常用的研究方法,它具有通量高、灵敏度高、分辨率高、限制性小等特点[15],近年来,其在油茶上的应用也逐渐增多。林萍等[16]初次在油茶研究中采用solexa测序技术进行分析,初步展示了油茶种子发育过程中基因组的表达图谱,并阐明了部分编码蛋白的代谢通路。江南等[17]以普通油茶的种子为材料,利用转录组测序技术挖掘出12个油茶发育过程中调控α-亚麻酸合成的关键酶基因。吕晓杰等[18]通过对3个不同时期的油茶籽进行转录组测序,研究了与脂肪酸和甘油三酯代谢相关的4 个关键酶基因。曾艳玲等[19]通过RNA-Seq技术对油茶中WRKY 转录因子及植物萜类物质合成进行了分析。卿卓等[20]采用高通量Illumina Hiseq测序手段对红花油茶(Camellia reticulata)花蕾期和泌蜜高峰期的蜜腺进行转录组测序,得到了与花蜜化学组成调控过程有关的差异表达基因。
本研究通过对“万海1号”和“万海4号”2个海南本地油茶优良品种进行转录组测序分析,丰富了其遗传资源。对“万海1号”和“万海4号”各自的特异性表达基因的进行GO和KEGG富集分析,结果表明,“万海4号”的基因富集结果中,出现了倍半萜和三萜生物合成、油菜素类固醇生物合成、类固醇生物合成和单萜类生物合成等与植物次生代谢相关的途径。而在“万海1号”的富集结果中则出现了脂肪酸生物合成及脂肪酸代谢等与脂肪酸相关的途径,这与油茶的茶籽、茶油品质息息相关。另外,在“万海1号”的KEGG富集结果中,富集基因数最多的1条分支为植物病原体互作途径,表明“万海1号”特异性基因与油茶抗病性的关联,2个样品共同基因的表达谱分析也验证了此结果。对2个样品中富集特异性基因较多的KEGG通路进行统计,总结出部分二者共有的富集途径,其中,有2条与代谢相关的途径:碳代谢和氨基酸的生物合成;还有4条与遗传信息处理相关的途径,分别是内质网中的蛋白质加工、核糖体、RNA转运和剪接体;还有1条胞吞作用途径,与细胞过程相关。
在此基础上,笔者通过Ka/Ks筛选出2个样品单拷贝同源基因中受到强烈正向选择的基因,进一步进行GO和KEGG注释,结果表明,某些单拷贝同源基因被富集到与抗氧化能力相关的GO条目,如“GO:0006801-超氧化物代谢过程”、“GO:0016655-氧化还原酶活性,作为NAD(P)H,醌或类似化合物的受体”等条目,显示出与抗氧化能力及油茶抗病性的相关性。KEGG富集分析显示:基因多被富集到与氨基酸合成代谢相关的条目,如“精氨酸和脯氨酸代谢”、“嘌呤代谢”,以及与生物碱合成代谢相关的条目,如“莨菪烷、哌啶和吡啶生物碱的生物合成”、“异喹啉生物碱的生物合成”,且P值均小于0.05,显示出显著的相关性。
本研究结果表明,“万海1号”特异性基因中,有相当一部分与其抗病性及脂肪酸代谢相关,而“万海4号”的特异性基因则表现出与植物次生代谢的相关性,2个样本的单拷贝同源基因多显示出与抗氧化能力及氨基酸合成代谢的相关性。因此,“万海1号” 油茶可能具有较强抗逆性,而“万海4号”油茶可能积累了更多的次生代谢产物。在此基础上,笔者建议可设计进一步实验,验证“万海1号”和“万海4号”油茶中与抗逆、抗病、次生代谢合成等品质有关的基因,从而对海南本地油茶的生理及代谢过程进行分子层面的调控,为海南本地油茶的优良品种选育和改良提供可靠的科学依据。
 DownLoad:
DownLoad: